


Something is happening, but you don't know what it is
Exploring the limits of Large Language Models (LLMs) and the challenge of finding quality data to train them in the digital world.


I borrowed the title from a verse of a Bob Dylan song that I love, Ballad of a Thin Man, but it could well be “the snooker of LLMs”. Or even the question “where does the content of generative AIs come from?”.
It's no surprise to those in the industry that we are running out of data to train new versions of Large Language Models (LLMs). If anyone is interested, I recorded two introductory videos on LLMs, with a technical approach that is more accessible to laypeople – Portuguese only, sorry folks – part 1 e part 2). The question is how close we are to the limit. This week, I spoke with some colleagues about the subject. In particular, Mark Cummins, shared some estimates of the total amount of Internet text available in the world. Mark's estimate is based on the main public and private sources that exist today.
Let's use Llama 3 as a baseline (those who watch the videos will understand why Llama is used for benchmarking). Llama 3 was trained on 15 trillion tokens (equivalent to approximately 11 trillion words), as shown in Table 1. For comparison, according to Mark, this amount is roughly 100,000 times what a human being needs to learn a language.
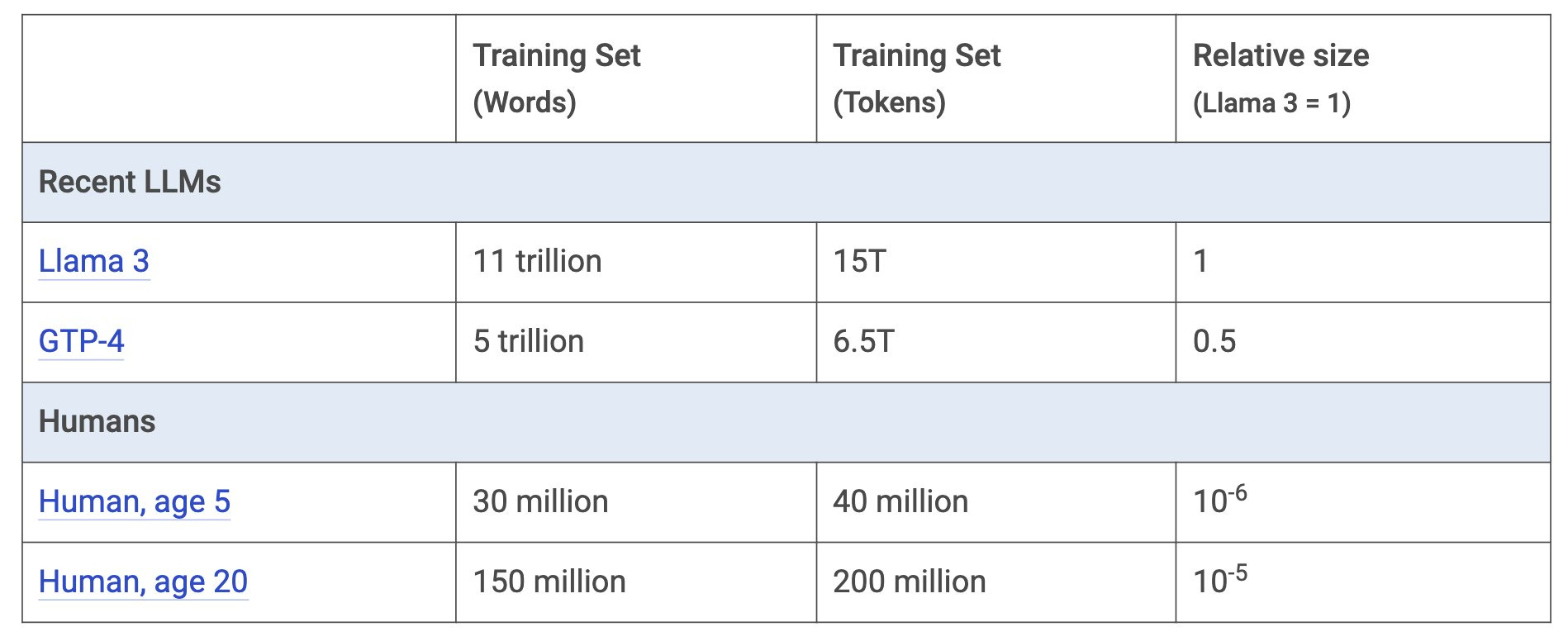
Table 1: Scale of most recent LLMs. Source: Mark Cummins.
The main source of data for training a LLM is gathered from the web through web scraping. Web scraping is a text mining technique performed using a web crawler, which browses the World Wide Web, downloading internet pages (websites, documents, videos, images, and other content). Repositories like Common Crawl make it easy to obtain billions of pages that have been collected over the years. From Common Crawl, for example, it is possible to extract more than 100 trillion tokens, although much of this material consists of garbage or duplicate pages.
There are some filtered datasets available with higher quality tokens, such as Fineweb, which contains approximately 15 trillion tokens (see Table 2).
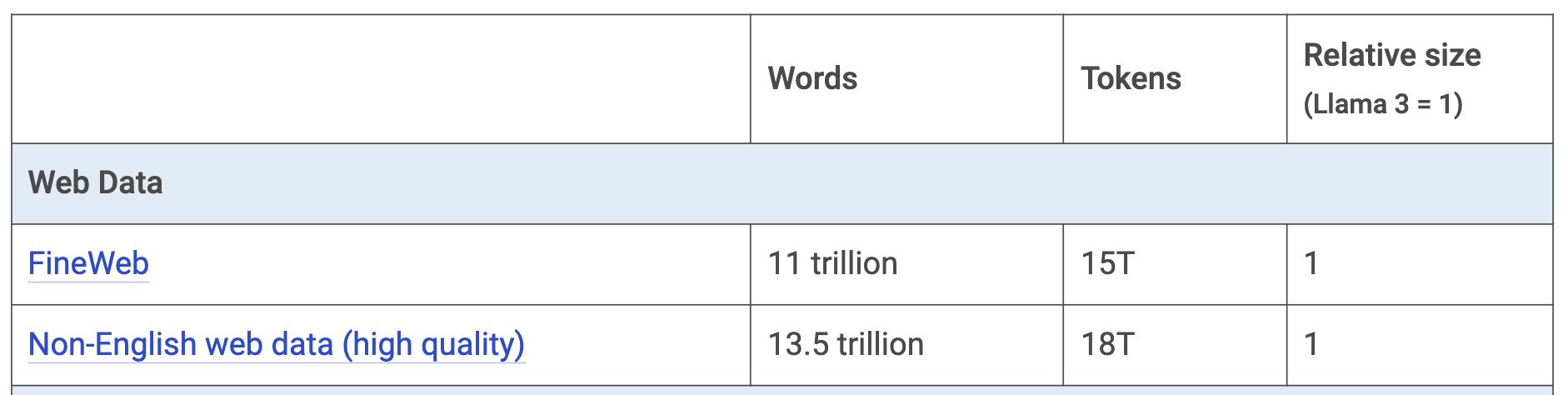
Table 2: Qualified Web Data. Source: Mark Cummins.
If the most attentive readers compare the two tables, they will realize that Llama 3 was trained with almost all the quality English text available on the Internet.
English accounts for approximately 45% of the Web. In principle, it would be possible to increase the data available for training using multilingual text. However, empirically, this does not benefit current models, which primarily learn in English. Although we can communicate with models like ChatGPT in other languages, the AI itself "understands" and "speaks" only English (there is a translation stage that enables multilingual communication). Therefore, it is necessary to develop a new training method that can effectively utilize multilingual data.
Datasets like those provided by Common Crawl and FineWeb are primarily composed of HTML content. Any content available as a PDF or dynamically rendered is ignored. Content behind a login (proprietary materials) is rarely captured. Therefore, there is more data available in different formats that could be used. Let's see some examples:
Academic papers and patents (see Table 3) could add around 1.2 trillion tokens. Extracting content from PDFs requires more effort, but their high-quality text makes them very valuable. The key is to reach a financial agreement with the content owners (if it is not published as open data).

Table 3: Estimation of tokens coming from academic papers and patents. Source: Mark Cummins.
Books are another excellent source of content, but they are less accessible. For example, Google Books could provide almost 5 trillion tokens (see Table 4), but this resource is only available to Google. It may even be the largest proprietary source of high-quality tokens in existence.

Table 4: Estimated tokens coming from books. Source: Mark Cummins.
Anna's Archive is a shadow library (formerly known as "pirate") with almost 4 trillion e-book tokens. While obtaining this content poses numerous legal issues, it would not be a significant technical challenge if someone decided it was worth "capturing" this material (after all, as the old spanish saying goes "a thief who robs a thief..."). In any case, e-books, in general, could provide another 21 trillion tokens.
Let's talk about social media now (see Table 5). X (formerly Twitter) could generate around 11 trillion tokens, and Weibo (the Chinese equivalent of Twitter) could generate another 38 trillion. I confess that these numbers surprised me, but I believe that if we perform quality filtering, the numbers should drop significantly. Facebook is even bigger, with Mark estimating it at 140 trillion tokens, though it could be even larger (Zuckerberg and co. are sitting on a veritable gold mine). However, data privacy legislation indicates that this material will probably not be used.

Table 5: Estimated tokens coming from social media. Source: Mark Cummins.
At the release of Llama 3, it was reported that "no Meta user data was used", despite Zuckerberg himself boasting that he has a corpus larger than the entire Common Crawl. I believe that, at least in the short term, this content can be considered off-limits.
Transcribed audio (see Table 6) is another considerable source of publicly available tokens. It is widely accepted that OpenAI developed Whisper (a neural network for speech recognition) for this purpose. YouTube and TikTok have 7 trillion and 5 trillion tokens, respectively. Podcasts are a tenth of this size but are of much higher quality, which also makes them very valuable.

Table 6: Estimated tokens coming from transcribed audio. Source: Mark Cummins.
The content of digitized TV files is very small and possibly not worth the effort. Radio could potentially provide a few trillion tokens if digitized into good files, but unfortunately, this content is small and fragmented. In practice, it would not be possible to obtain more than a few hundred billion tokens, which is less than what is available from podcasts.
Next, we have programming codes (see Table 7). Code is a very important type of text for AI (don't forget, it is the "language" of computers). There are 0.75 trillion public code tokens available in repositories like GitHub or in developer Q&A communities like StackOverflow. The total amount of code written to date may reach 20 trillion tokens, although much of it is private or lost.
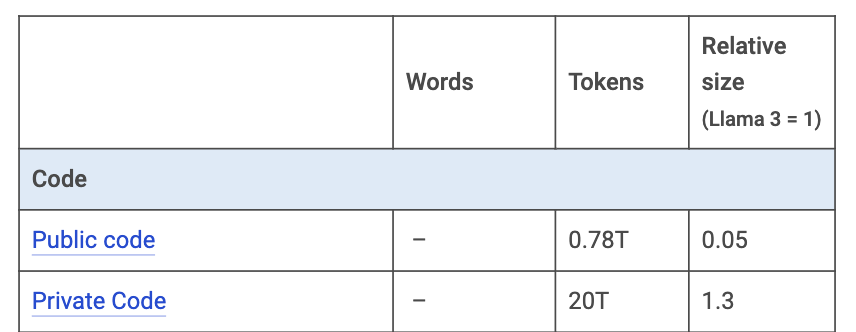
Table 7: Estimation of tokens coming from programming codes. Source: Mark Cummins.
Next, we come to private data (see Table 8). There is much more private data than public data. For example, instant messaging records could reach 650 trillion tokens, and stored emails could reach 1,200 trillion. It is estimated that Gmail alone holds 300 trillion tokens. Just like Zuckerberg, Larry Page and Sergey Brin are sitting on a gold mine, although they are subject to the same privacy restrictions as Meta.

Table 8: Estimation of tokens coming from private data. Source: Mark Cummins.
Mark told me he can't imagine any commercial LLM making extensive use of this data due to obvious privacy concerns. However, an intelligence agency, like the NSA or CIA, might be able to. In any case, his estimate for the total content generated by humans is gigantic (see Table 9).
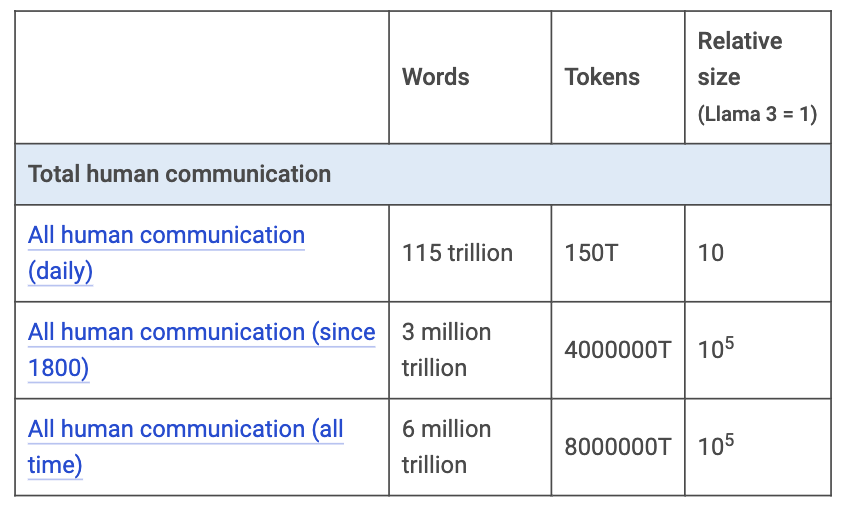
Table 9: Estimation of tokens generated by humans. Source: Mark Cummins.
If this data were digitized or funneled into AI training, there would be no limit to the content available. However, this is not the reality. Current LLMs are trained with 15 trillion public tokens. With significant effort, we might expand to 25 or 30 trillion, but not much more. Including non-English data, we could reach 60 trillion tokens. This seems to be the maximum limit of available content.
Private data is much larger than the public data currently used. Facebook posts exceed 140 trillion tokens, Google has about 300 trillion tokens in Gmail, and all private data combined can generate 2,000 trillion tokens. It is possible to develop privacy-preserving techniques that allow training public models on private data, but the potential consequences of an error are so great that I cannot imagine this happening, at least in the short term.
To conclude, we have 15 trillion tokens available right now. Even with a massive effort, there is at most 2 to 4 times more content available in public data. Historically, the jump between each model generation required 10 times more training data. Therefore, new ideas to "feed" AI learning will be needed soon. Is it a snooker or not?